
SRE:A Deep Dive into CloudXShift’s Cutting-Edge Technologies
SRE (Site Reliability Engineering) is a set of practices and principles that focus on reliability, scalability, and maintainability of systems. In this article, we will explore the SRE practices and principles that can help create highly reliable and scalable systems.
SRE Practices:
- Service Level Objectives (SLOs): Service Level Objectives (SLOs) are critical to ensuring that a system meets the expected reliability and performance standards. An SLO is a measurable target for the availability, performance, or reliability of a system. The SLOs should be defined in collaboration with the business and the development team, and they should be realistic and achievable. SRE teams measure SLOs continuously and use the results to identify areas for improvement.
- Error Budgets: An Error Budget is a key SRE concept that ensures that the system is reliable and scalable. The Error Budget is the maximum amount of downtime or errors allowed for a system over a given period. The SRE team manages the Error Budget, and if the system is down or degraded, they use the Error Budget to determine if the issue was within the acceptable range. If the Error Budget is exceeded, the SRE team implements changes to prevent similar issues from occurring in the future.
- Monitoring and Alerting: Monitoring and Alerting are critical to detecting and responding to system issues quickly. SRE teams use monitoring tools to collect data on system health and performance, and they use alerting tools to notify them when the system is down or degraded. The SRE team can then respond quickly to resolve the issue before it becomes critical.
- Incident Management: Incident Management is a well-defined process that enables SRE teams to quickly and effectively resolve system issues. The Incident Management process includes defining the incident, assessing the impact, identifying the root cause, implementing a temporary fix, implementing a permanent fix, and conducting a post-incident review.
- Post-Incident Review: Post-Incident Review is critical to identifying the root cause of the issue and preventing similar issues from occurring in the future. The SRE team conducts a post-incident review after every incident to identify areas for improvement and implement changes to prevent similar incidents.
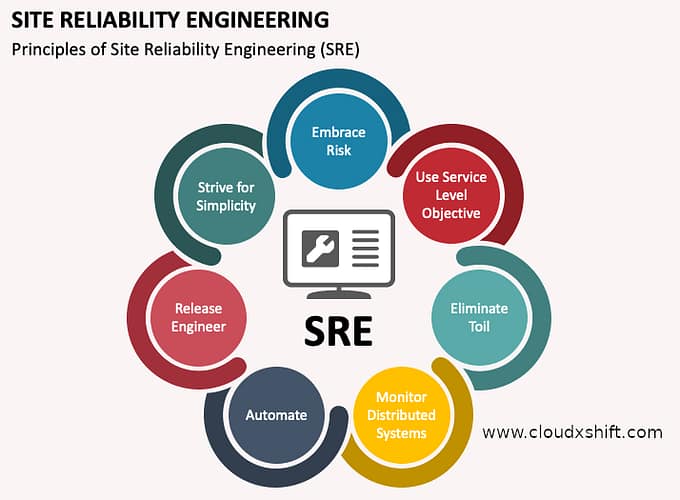
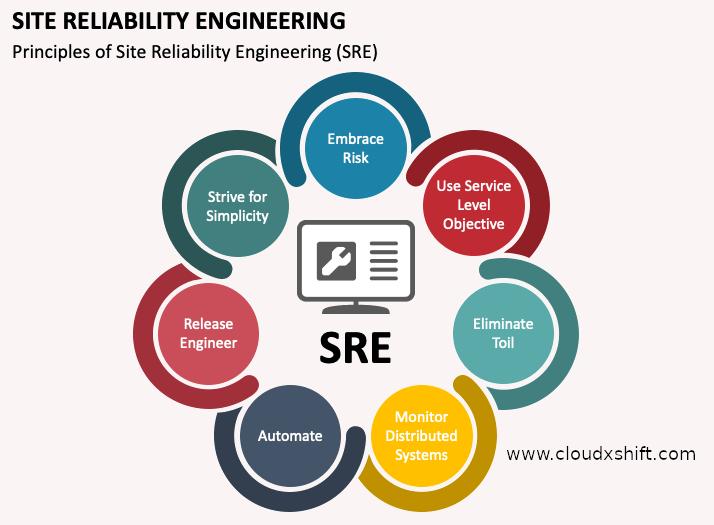
SRE Principles:
- Automation: Automation is critical to increasing the reliability and scalability of a system. SRE teams use automation to reduce manual work, reduce the risk of human error, and increase the speed of deployment. Automation can include automated testing, deployment, and monitoring.
- Design for Failure: Designing for failure is critical to building systems that can handle failures gracefully. SRE teams design systems with redundancy, failover mechanisms, and graceful degradation to ensure that the system remains available even in the event of failures.
- Simplicity: Simplicity is critical to reducing complexity-related failures and making it easier to diagnose and resolve issues. SRE teams prioritize simplicity in system design and operation, which includes reducing the number of components and dependencies, minimizing configuration complexity, and prioritizing standardization.
- Scalability: Scalability is critical to building systems that can handle growing user demand. SRE teams design systems that can scale horizontally and vertically, implement auto-scaling mechanisms, and use load balancing to ensure that the system can handle large amounts of traffic.
- Continuous Improvement: Continuous Improvement is critical to improving the reliability and scalability of a system over time. SRE teams continuously identify areas for improvement, implement changes, and measure the impact of those changes to ensure that the system is always improving.
Benefits of SRE:
- Improved Reliability: SRE practices and principles improve system reliability by proactively identifying and addressing issues. This results in fewer incidents, faster incident resolution times, and higher availability for the system.
- Increased Scalability: SRE practices and principles increase system scalability by designing for scalability and implementing auto-scaling mechanisms. This ensures that the system can handle growing user demand without sacrificing performance or reliability.
- Improved Performance: SRE practices and principles improve system performance by implementing monitoring and alerting, identifying and addressing bottlenecks, and continuously improving the system over time. This results in faster response times, higher throughput, and better user experience.
- Reduced Downtime: SRE practices and principles help reduce system downtime by proactively identifying and addressing issues, implementing redundancy and failover mechanisms, and using automation to reduce the risk of human error. This results in less downtime and faster incident resolution times.
- Increased Efficiency: SRE practices and principles increase system efficiency by reducing manual work and automating processes. This results in faster deployment times, faster incident resolution times, and reduced operational costs.
- Improved Customer Satisfaction: SRE practices and principles result in higher system reliability, better performance, and less downtime, which ultimately lead to improved customer satisfaction. This is critical to ensuring that customers are happy with the system and continue to use it.
In conclusion, SRE practices and principles are critical to building highly reliable and scalable systems. By implementing SRE practices such as Service Level Objectives, Error Budgets, Monitoring and Alerting, Incident Management, and Post-Incident Review, and principles such as Automation, Design for Failure, Simplicity, Scalability, and Continuous Improvement, SRE teams can improve system reliability, scalability, performance, efficiency, and customer satisfaction. SRE is a key part of modern software development and operations, and its benefits are essential to organizations that require highly reliable and scalable systems to meet business needs.
Further Readings
DevOps Adoption and Implementation
Praveen Rana
Author is Cloud Strategist with an Expertise in the design and delivery of cost - effective, high-performance information technology infrastructures and applications solution to address complex business problems.




One Comment
Pingback: